
因為 Kafka 依賴 ZooKeeper 來處理分散式系統的備援機制,以下由 Kafka 的安裝與測試,進一步討論如何用 Scala 來撰寫 Producer 與 Consumer。
ZooKeeper Server
Zookeeper 提供目錄和節點的服務,當有兩台伺服器啟動時,會在zookeeper的指定目錄下創建對應自己的臨時節點(這個過程稱為“註冊”),所謂臨時節點,是靠 heartbeat(定時向zookeeper伺服器發送訊息)維持,當伺服器出現故障,zookeeper 就會刪除臨時節點。當伺服器向zookeeper註冊時,zookeeper會分配序列號,我們認為序列號小的那個,就是“主”,序列號大的那個,就是“備援機”(slave)。
當有客戶端需要使用“寫”服務時,需要連接zookeeper,獲得指定目錄下的臨時節點列表,也就是已經註冊的伺服器信息,取得序列號小的那台“主”伺服器的地址,進行後續的訪問操作。以達到“總是訪問主伺服器”的目的。
接下來處理 ZooKeeper 的設定,首先下載 kafka
wget http://apache.stu.edu.tw/kafka/0.9.0.1/kafka_2.10-0.9.0.1.tgz
tar zxvf kafka_2.11-0.9.0.1.tgz因為 kafka 必須要連結到 ZooKeeper,所以在啟動 kafka server 之前,必須要先啟動 ZooKeeper,通常 ZooKeeper cluster 以三個節點互相備援,且必須要分散配置在三台機器上,目前只是前期測試,就先只啟動一個 ZooKeeper server。
ZooKeeper 的設定檔在 config/zookeeper.properties 裡面,看一下內容,用到 /tmp/zookeeper 這個資料夾,並使用到 TCP Port 2181 作為服務的 port:
# the directory where the snapshot is stored.
dataDir=/tmp/zookeeper
# the port at which the clients will connect
clientPort=2181
# disable the per-ip limit on the number of connections since this is a non-production config
maxClientCnxns=0如果為了未來調整設定方便,可以設定環境變數 KAFKA_HOME
KAFKA_HOME=/root/download/kafka/kafka_2.11-0.9.0.1啟動 ZooKeeper Server
nohup $KAFKA_HOME/bin/zookeeper-server-start.sh $KAFKA_HOME/config/zookeeper.properties &在啟動指令,加上 -daemon 也可以,這應該是比剛剛的方法還正確的方式
$KAFKA_HOME/bin/zookeeper-server-start.sh -daemon $KAFKA_HOME/config/zookeeper.properties關閉 ZooKeeper Server
$KAFKA_HOME/bin/zookeeper-server-stop.sh $KAFKA_HOME/config/zookeeper.properties &啟動完成後,會在 netstat 裡面看到 TCP 2181 Port
# netstat -tnlp|grep 2181
tcp 0 0 0.0.0.0:2181 0.0.0.0:* LISTEN 30841/java我們也可以使用 Apache ZooKeeper 的套件包 zookeeper-3.4.8.tar.gz,不要用 Kafka 內建的 zookeeper。
ZOOKEEPER_HOME=/root/download/kafka/zookeeper-3.4.8
cp $ZOOKEEPER_HOME/conf/zoo_sample.cfg $ZOOKEEPER_HOME/conf/zoo.cfg啟動 zookeeper server
$ZOOKEEPER_HOME/bin/zkServer.sh start查看 zookeeper server status
$ZOOKEEPER_HOME/bin/zkServer.sh statusKafka Broker
因為 Kafka 可以設定 replication-factor,讓資料複製到多個 Broker。
Kafka Broker server 的設定檔在 config/server.properties 裡面,首先要在設定檔中加上這一行,讓我們可以刪除 topic。
delete.topic.enable=true然後看設定檔的最前面,broker.id 以及 listeners的設定,這是在多個 broker 時,有需要調整的設定項目。
broker.id=0
listeners=PLAINTEXT://:9092
# The port the socket server listens on
port=9092
# A comma seperated list of directories under which to store log files
log.dirs=/tmp/kafka-logs
# Zookeeper connection string (see zookeeper docs for details).
zookeeper.connect=localhost:2181如果只要執行一個 Kafka Broker 測試,直接這樣執行就好了,因為接下來要安裝 kafka-manager,所以啟動時順道加上 JMX_PORT 的資訊。
env JMX_PORT=8092 $KAFKA_HOME/bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties如果要再執行兩個 Broker,要先把設定檔調整好
cp config/server.properties config/server-1.properties
cp config/server.properties config/server-2.properties調整 config/server-1.properties
broker.id=1
listeners=PLAINTEXT://:9093
log.dirs=/tmp/kafka-logs-1
delete.topic.enable=true調整 config/server-2.properties
broker.id=2
listeners=PLAINTEXT://:9094
log.dirs=/tmp/kafka-logs-2
zookeeper.connect=localhost:2181接下來再啟動兩個 kafka servers
env JMX_PORT=8093 $KAFKA_HOME/bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server-1.properties
env JMX_PORT=8094 $KAFKA_HOME/bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server-2.propertiesnetstat 可看到這三個 Brokers 的 Port
# netstat -tnlp|grep 909
tcp 0 0 0.0.0.0:9092 0.0.0.0:* LISTEN 2694/java
tcp 0 0 0.0.0.0:9093 0.0.0.0:* LISTEN 3593/java
tcp 0 0 0.0.0.0:9094 0.0.0.0:* LISTEN 3657/javaTopic
啟動 Kafka Broker 之後,必須先建立 topic。
因為我們只有三個 Broker,所以 replication-factor 只能指定為 3,如果指定為 4,就會發生 kafka.admin.AdminOperationException。
$KAFKA_HOME/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 4 --partitions 1 --topic test
Error while executing topic command : replication factor: 4 larger than available brokers: 3
[2016-02-26 16:17:15,436] ERROR kafka.admin.AdminOperationException: replication factor: 4 larger than available brokers: 3
at kafka.admin.AdminUtils$.assignReplicasToBrokers(AdminUtils.scala:77)
at kafka.admin.AdminUtils$.createTopic(AdminUtils.scala:236)
at kafka.admin.TopicCommand$.createTopic(TopicCommand.scala:105)
at kafka.admin.TopicCommand$.main(TopicCommand.scala:60)
at kafka.admin.TopicCommand.main(TopicCommand.scala)
(kafka.admin.TopicCommand$)所以我們將 replication-factor 改為 3
$KAFKA_HOME/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic test
Created topic "test".可以用指令查看 kafka-topic 的資訊,ReplicationFactor是3份, Replicate 在 0, 1, 2 這三台broker上面, topic的leader是 broker id 0,leader負責 partition 的read and write。Isr的意思是有哪些 broker 正在同步當中,簡單的說可以知道哪些broker是活著的。
$KAFKA_HOME/bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
Topic:test PartitionCount:1 ReplicationFactor:3 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2可以用以下指令刪除 topic
$KAFKA_HOME/bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic test刪除了 test 這個 topic 之後,就查不到 topic 的資訊了
Message Producer Consumer 測試
啟動 Console Producer,啟動後會進入互動模式,可以一直往 test 這個 topic 發送文字訊息。
$KAFKA_HOME/bin/kafka-console-producer.sh --broker-list localhost:9092,localhost:9093,localhost:9094 --topic test啟動 Console Consumer,這裡要注意的是,Consumer 是連結到 ZooKeeper 而不是直接連到 Broker,--from-beginning 這個參數的意思是要從頭開始,而不是從連結的時候開始。
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning如果在啟動 consumer 之前,已經在 producer 對 topic: test 發送了幾個訊息,那啟動 consumer 如果有加上 --from-beginning 這個參數,就會把先前那幾個訊息也列印出來。
如果沒有加上 --from-beginning 這個參數,就會從啟動 consumer 開始接收後面的訊息。
列印所有 consumer group 的資訊
bin/kafka-consumer-groups.sh --zookeeper localhost:2181 --list刪除 consumer group: test
bin/kafka-consumer-groups.sh --zookeeper localhost:2181 --delete -group testyahoo kafka-manager
Yahoo 對 Kafka 開發了一個 kafka-manager 網頁管理介面
我們在這個連結下載 kafka-manager 1.3.0.4.tar.gz
解壓縮後,利用 sbt 就可以建置 kadka-manager 的 production deployment package
sbt clean dist可以在這個目錄中,找到編譯後的 zip file
kafka-manager-1.3.0.4/target/universal/kafka-manager-1.3.0.4.zip
KAFKA_MANAGER_HOME=/root/download/kafka/kafka-manager-1.3.0.4解壓縮 kafka-manager-1.3.0.4.zip 可以看到 bin, conf, lib, share 這些資料夾。
首先修改 conf/application.conf 裡面的 zkhosts
kafka-manager.zkhosts="192.168.1.7:2181"然後用這個指令,啟動 kafka-manager
nohup $KAFKA_MANAGER_HOME/bin/kafka-manager -Dconfig.file=$KAFKA_MANAGER_HOME/conf/application.conf -Dhttp.port=9000 > /dev/null 2>&1依照這個畫面的資訊,把 zookeeper 加入 kafka cluster list
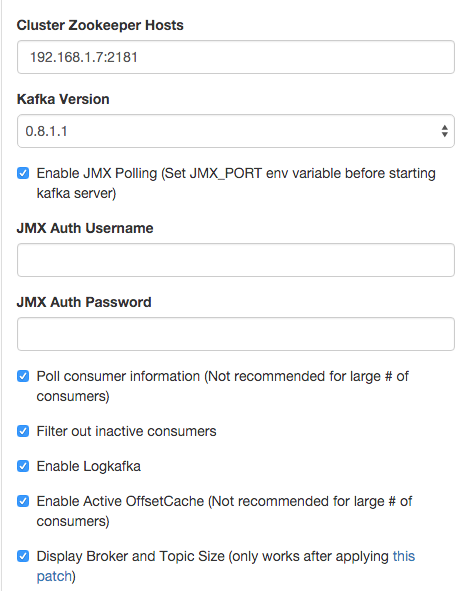
接下來就可以用網頁查看 Kafka cluster 的資訊

References
Deploy Apache Kafka Cluster on AWS


