
根據這兩個網址的說明,安裝 Google Voice Kit V1
一口氣將 Voice Kit 連上 Google Cloud Platform — 實作篇
note: 注意變壓器必須要輸出 5V 2.5A,電流不夠會讓 RPi 一直 reboot
Voice HAT (Hardware Attached on Top)
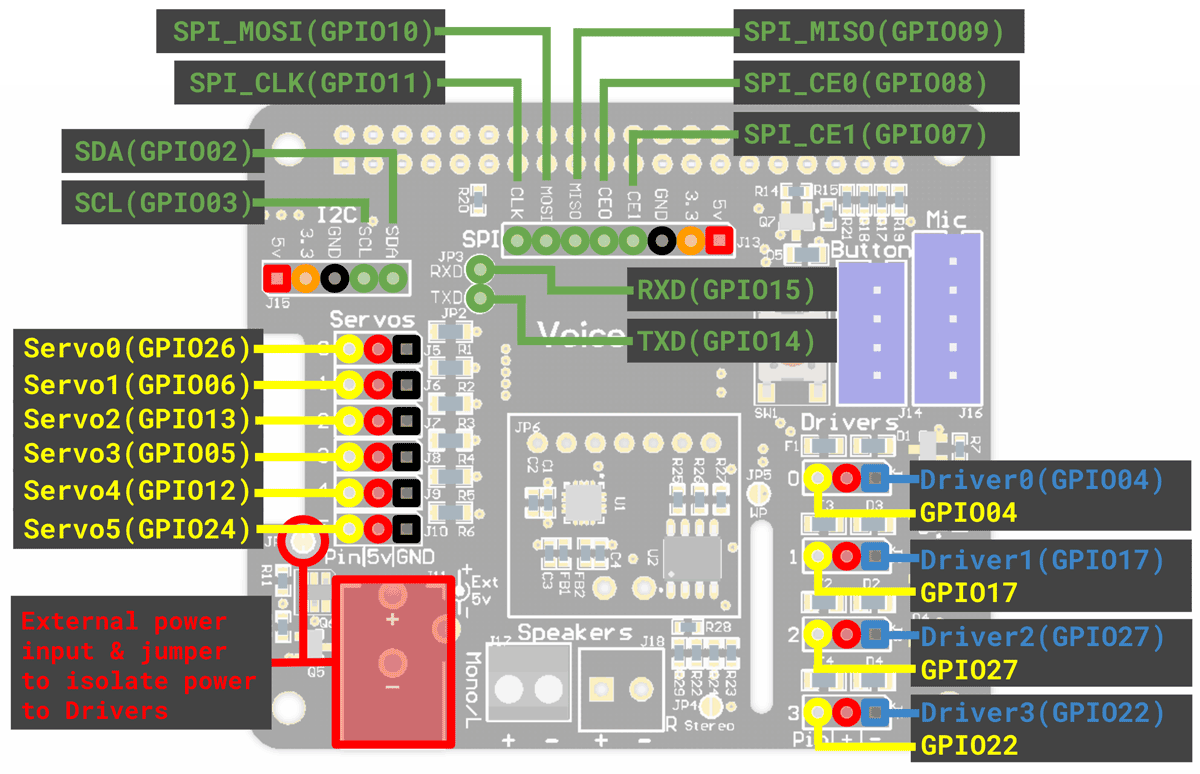

傳感器常用的 I2C, UART(14,15 還特意分出來了), SPI 都沒有佔用。 其餘的 GPIO 分為兩組並配備了電源接口,可以直接用作 GPIO,也可以控制外部設備:
- Servo0-Servo5:5v/25mA,小電流的 Servo 適合連接類似 LED 之類的設備。
- Dirver0-Driver4:5v/500mA,可以連接功率更大的設備 (例如 小車的馬達),+/- 極來自在板子左下角的外接電源。可以參考這個接法:https://www.raspberrypi.org/magpi/motor-aiy-voice-pi/
使用 Speech Recognition API & gTTS 套件
用 Speech Recognition API 辨識中/英文
用 gTTS 套件說中文
gTTS: a Python library and CLI tool to interface with Google Translate's text-to-speech API,這是用 python 透過 google translate 轉換為語音的套件
沒有智能語義 AI,不是 Google assistent
需要產生服務帳戶金鑰
由 Google Cloud Platform GCP 產生服務帳戶金鑰,並存放到 /home/pi/cloud_speech.json
測試程式 cloudspeech_demo.py
安裝 gTTS 相關套件
sudo python3 -m pip install gTTS
sudo python3 -m pip install pydub
sudo apt install ffmpeg修改後的 cloudspeech_demo.py
#!/usr/bin/env python3
# Copyright 2017 Google Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""A demo of the Google CloudSpeech recognizer."""
import argparse
import locale
import logging
from aiy.board import Board, Led
from aiy.cloudspeech import CloudSpeechClient
from aiy.voice import audio
from gtts import gTTS
from pydub import AudioSegment
def get_hints(language_code):
if language_code.startswith('en_'):
return ('turn on the light',
'turn off the light',
'blink the light',
'goodbye')
return None
def locale_language():
language, _ = locale.getdefaultlocale()
return language
def say(text, lang=None):
if lang == None:
tts = gTTS(text)
else:
tts = gTTS(text, lang)
# 把文字變成gtts內建的物件
tts.save('output.mp3') # 把得到的語音存成 output.mp3
sound = AudioSegment.from_mp3('output.mp3') # 把 output.mp3 讀出
sound.export('output.wav', format='wav') # 轉存成 output.wav
audio.play_wav('output.wav') # 把 wav 用 VoiceKit 播出來
def main():
# say('test')
logging.basicConfig(level=logging.DEBUG)
parser = argparse.ArgumentParser(description='Assistant service example.')
parser.add_argument('--language', default=locale_language())
args = parser.parse_args()
logging.info('Initializing for language %s...', args.language)
hints = get_hints(args.language)
client = CloudSpeechClient()
with Board() as board:
while True:
if hints:
logging.info('Say something, e.g. %s.' % ', '.join(hints))
else:
logging.info('Say something.')
text = client.recognize(language_code=args.language,
hint_phrases=hints)
if text is None:
logging.info('You said nothing.')
continue
logging.info('You said: "%s"' % text)
text = text.lower()
if 'turn on the light' in text:
board.led.state = Led.ON
say('light is on')
elif 'turn off the light' in text:
board.led.state = Led.OFF
say('light is off')
elif 'blink the light' in text:
board.led.state = Led.BLINK
say('light is blinked')
elif '開燈' in text:
board.led.state = Led.ON
say('燈開好了', 'zh-TW')
elif '關燈' in text:
board.led.state = Led.OFF
say('燈關了', 'zh-TW')
elif '閃燈' in text:
board.led.state = Led.BLINK
say('閃燈中', 'zh-TW')
elif 'bye' in text:
say('bye')
break
elif '結束' in text:
say('再見', 'zh-TW')
break
elif 'goodbye' in text:
say('bye')
break
if __name__ == '__main__':
main()調整音量的指令
alsamixernote:
pip3 install gTTS 出現 Error
Exception:
Traceback (most recent call last):
File "/usr/share/python-wheels/urllib3-1.19.1-py2.py3-none-any.whl/urllib3/connectionpool.py", line 594, in urlopen
chunked=chunked)
File "/usr/share/python-wheels/urllib3-1.19.1-py2.py3-none-any.whl/urllib3/connectionpool.py", line 391, in _make_request
six.raise_from(e, None)
File "<string>", line 2, in raise_from
File "/usr/share/python-wheels/urllib3-1.19.1-py2.py3-none-any.whl/urllib3/connectionpool.py", line 387, in _make_request
httplib_response = conn.getresponse()
File "/usr/lib/python3.5/http/client.py", line 1198, in getresponse
response.begin()
File "/usr/lib/python3.5/http/client.py", line 297, in begin
version, status, reason = self._read_status()
File "/usr/lib/python3.5/http/client.py", line 266, in _read_status
raise RemoteDisconnected("Remote end closed connection without"
http.client.RemoteDisconnected: Remote end closed connection without response
During handling of the above exception, another exception occurred:
......
TypeError: unsupported operand type(s) for -=: 'Retry' and 'int'解決方式:更新 requests
sudo python3 -m pip install --user --upgrade requests解決方法:改用這個指令安裝
sudo python3 -m pip install gTTS使用 Google Assistant Service API
需要產生 OAuth 用戶端 ID
note 設定過程中,會綁定到某一個帳號:
charley@maxkit.com.tw google assistent auth code
4/qQGwcp38dePn7QQABHiXJwgS2Hhs6Jz6hG3sVX9l2Y6WIoUXgt5bFVo存放到 /home/pi/assistant.json
程式使用內建 pico2wave 來合成語音,故不支援中文
demo 程式
~/AIY-projects-python/src/examples/voice/assistantlibrarydemo.py
要說
Hey Google然後再問問題,只支援英文~/AIY-projects-python/src/examples/voice/assistantlibrarywithbuttondemo.py
要說
Hey Google或是按下按鈕,然後再問問題,只支援英文assistantgrpcdemo.py
~/AIY-projects-python/src/examples/voice/ ./assistant_grpc_demo.py
將 assitant demo 設定為開機自動啟動
ref: GOOGLE VOICE KIT AUTOSTART
sudo vim /etc/systemd/system/assistant.service
[Unit]
Description=Google Assistant
Wants=network-online.target
After=network-online.target
Wants=systemd-timesyncd.service
After=systemd-timesyncd.service
[Service]
Environment=DISPLAY=:0
Type=simple
ExecStart=/home/pi/AIY-projects-python/src/examples/voice/assistant_library_with_button_demo.py
Restart=on-failure
User=pi
Group=pi
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=google_assistant
[Install]
WantedBy=multi-user.targetsudo chmod 755 /etc/systemd/system/assistant.service
sudo systemctl daemon-reload
sudo systemctl enable assistant.service
sudo service assistant start查閱 log
sudo journalctl -u assistant -f客製化 hotword
ref: 語音喚醒技術的原理是什麼?
ref: 語音喚醒
語音喚醒在學術上被稱為keyword spotting(簡稱KWS),吳老師給它做了一個定義:在連續語流中實時檢測出說話人特定片段。
這裡要注意,檢測的「實時性」是一個關鍵點,語音喚醒的目的就是將設備從休眠狀態激活至運行狀態,所以喚醒詞說出之後,能立刻被檢測出來,用戶的體驗才會更好。
那麼,該怎樣評價語音喚醒的效果呢?通行的指標有四個方面,即喚醒率、誤喚醒、響應時間和功耗水平:
➤喚醒率,指用戶交互的成功率,專業術語為召回率,即recall。
➤誤喚醒,用戶未進行交互而設備被喚醒的概率,一般按天計算,如最多一天一次。
➤響應時間,指從用戶說完喚醒詞後,到設備給出反饋的時間差。
➤功耗水平,即喚醒系統的耗電情況。很多智能設備是通過電池供電,需要滿足長時續航,對功耗水平就比較在意。
喚醒可以看成是一種小資源的關鍵詞檢索任務,其中小資源是指計算資源比較小和空間存儲資源比較小,因此它的系統框架跟關鍵詞檢索的系統會有一定的區別,目前常用的系統框架主要有Keyword/Filler Hidden Markov Model System和Deep KWS System兩種。
陳果果 kitt.ai 開發 DNN based snowboy 提供不同 OS 的 library,可自訂 hotword,百度在 2017 全資收購。
custom-hotword-for-aiy-voicekit
# 安裝 libatlas-base-dev
sudo apt-get install libatlas-base-dev
cd ~/AIY-voice-kit-python
src/examples/voice/assistant_grpc_demo_snowboy.py --language en-US --model src/mod/resources/alexa/alexa_02092017.umdl
# hotword: alexa
只有 alexa 可以用,其他的自訂 hotword,都沒辦法偵測到
note: 安裝 VNC
ref: [基礎] 以 VNC 和 Raspberry Pi 連線
ref: 基礎篇 - vnc連線
sudo apt-get install tightvncserver
vncserver
# 設定密碼在 vnc viewer 使用 192.168.1.175:5901 連線
沒有留言:
張貼留言