
語音辨識
ref: 微軟Edx語音識別課程
- 語音信號處理
- 聲學模型
- 語言模型
- 解碼器
語音活動偵測 VAD
聲學特徵分析
將聲音波形只代表聲壓隨時間變化的關係,必須將波形轉成聲學特徵向量:MFCC, LPCC, MRCG
以 MRCG 為基礎的分類器,以 tensorlfow (python 實作)
- ACAM 自我調整上下文關注模型
- bDNN 增強的深度神經網路
- DNN 深度神經網路
- LSTM-RNN 長短期記憶遞迴神經網路
標記語言
可用 IPA 或 SAMPA
SAMPA 是電腦讀取的語音字母表,包含將國際音標對應到 33~127 的 ASCII code
可用 audacity 標註音軌
可用 PRAAT 標記音節邊界
端點偵測 End-Point Detection
可自動檢測語音的起始及結束點。
可用雙門檻比較法進行端點偵測。以短時能量 E 和短時平均過零率 Z 作為特徵,進行端點偵測。
6-1 Introduction to End-Point Detection (端點偵測介紹)
常見的端點偵測方法與相關的特徵參數,可以分成兩大類:
- 時域(Time Domain)的方法:計算量比較小,因此比較容易移植到計算能力較差的微電腦平台。
- 音量:只使用音量來進行端點偵測,是最簡單的方法,但是會對氣音造成誤判。不同的音量計算方式也會造成端點偵測結果的不同,至於是哪一種計算方式比較好,並無定論,需要靠大量的資料來測試得知。
- 音量和過零率:以音量為主,過零率為輔,可以對氣音進行較精密的檢測。
- 頻域(Frequency Domain)的方法:計算量比較大,因此比較難移植到計算能力較差的微電腦平台。
- 頻譜的變異數:有聲音的頻譜變化較規律,變異數較低,可作為判斷端點的基準。
- 頻譜的Entropy:我們也可以使用使用 Entropy 達到類似上述的功能。
若只是對聲音波形做一些較簡單的運算,就是屬於時域的方法。另一方面,凡是要用到傅立葉轉換(Fourier Transform)來產生聲音的頻譜,就是屬於頻譜的方法。這種分法常被用來對音訊處的方法進行分類,但有時候有一些模糊地帶。有關於頻譜以及傅立葉轉換,會在後續的章節說明。
Sphinx Voice Activity Detection
錯誤的端點偵測,在語音辨識上會造成兩種效應:
- False Rejection:將 Speech 誤認為 Silence/Noise,因而造成音訊辨識率下降
- False Acceptance:將 Silence/Noise 誤認為 Speech,此時音訊辨識率也會下降,但是我們可以在設計辨識器時,前後加上可能的靜音聲學模型,此時辨識率的下降就會比前者來的和緩。
動態時間規劃
Dynamic Time Warping(DTW)動態時間規整演算法
Dynamic Time Warping(DTW)是一種衡量兩個時間序列之間的相似度的方法,主要應用在語音識別領域來識別兩段語音是否表示同一個單詞。
在時間序列中,需要比較相似性的兩段時間序列的長度可能並不相等,在語音識別領域表現為不同人的語速不同。而且同一個單詞內的不同音素的發音速度也不同,比如有的人會把“A”這個音拖得很長,或者把“i”發的很短。另外,不同時間序列可能僅僅存在時間軸上的位移,亦即在還原位移的情況下,兩個時間序列是一致的。在這些複雜情況下,使用傳統的歐幾里得距離無法有效地求的兩個時間序列之間的距離(或者相似性)。
DTW通過把時間序列進行延伸和縮短,來計算兩個時間序列性之間的相似性:
SH專區 - Dynamic Time Warping(動態時間規劃) 1
最基礎的DTW計算其實相當直覺,就是建構一個「點對點」的distance matrix,然後由起點一步一步的向終點邁進。在前進的時候,只有一個條件:挑選最短路徑。
數位語音資料
ref: Audio
要讓電腦處理聲音,必須預先讓聲音變成數字,也就是讓聲音經過「取樣 sampling 」與「量化 quantization 」兩個步驟。取樣把時間變成離散,量化把振幅 amplitude 變成離散。
先取樣(得到數列),再量化(四捨五入),最後得到一串整數數列。每個數字稱作「樣本 sample 」或「訊號 signal 」。

duration 持續時間:聲音總共多少秒。數值越高,訊號越多。
sampling rate 取樣頻率:一秒鐘有多少個訊號。數值越高,音質越好。電腦的聲音檔案,通常採用 48000Hz 或 44100Hz 。手機與電話的聲音傳輸,公定為 8000Hz 。
bit depth 位元深度:一個訊號用多少個位元記錄。數值越高,音質越好。電腦的聲音檔案,通常採用 16-bit 或 24-bit 。 16-bit 的每個訊號是 [-32768,+32767] 的整數,符合 C 語言的 short 變數。
channel 聲道:同時播放的聲音訊號總共幾條。每一條聲音訊號都是一樣長。舉例來說,民眾所熟悉的雙聲道,其實就是同時播出兩條不同的聲音訊號。
取樣頻率、持續時間、聲道,相乘之後就是訊號數量。再乘以位元深度,就是容量大小。再除以 8 ,可將單位換成 byte 。
順帶一提,不管是聲音或者是其他信息,只要是經過取樣與量化得到的資料,總稱 PCM data 。「脈衝編碼調變 pulse-code modulation, PCM 」源自訊號學,所以名稱才會如此不直覺。
各種聲音資料的位元深度不盡相同。統合方式:採用 32-bit 浮點數,讀檔後將訊號數值縮放成 [-1,+1] ,才進行聲音處理;存檔前調回原本範圍。
Amplitude 振幅
聲音訊號的數值,代表空氣振動的幅度。基準訂為 0 ,範圍訂為 ±32767 (當位元深度是 16-bit )。
振幅高,聽起來大聲。振幅低,聽起來小聲。

Frequency 頻率
人類擅於感受的不是振動的幅度,而是振動的頻率。頻率高,聽起來尖銳。頻率低,聽起來低沉。

取樣定理: x Hz 的波,取樣頻率至少要是 2x Hz ,才能明確分辨上下次數,頻率保持相同(而振幅總是失真)。也就是說,取樣頻率 48000Hz ,頂多只能記錄 24000Hz 以下的聲音。但是別擔心,人類聽覺範圍是 20Hz 至 20000Hz 。

frame 訊框
訊號很長,變化很大,因此必須將訊號分成小段處理,使得小段之內變化很小。每個小段都稱作一個「框」或「幀」。

當取樣頻率是 48000Hz 、框是 512 個訊號,則此框佔有 512/48000 ≈ 0.01 秒,人耳無法分辨這麼短時間的變化,人聲也無法控制這麼短時間的變化,可以說是足夠細膩了。
為了讓變化更連續,於是讓框交疊。
Fourier Transform
振動十分複雜,難以測量頻率。計算學家的共識是:運用離散版本 Fourier Transform ,將訊號數值分解成簡諧波,解析頻率。因為簡諧波是最漂亮的振動方式,所以適合當作公定標準。

spectrum 頻譜:一個特定時間點的頻率分佈圖。
實務上的做法是:截取一小段時間範圍的訊號,實施快速傅立葉轉換,得到每一種頻率的波的強度、相位。
比如 48000Hz 的取樣頻率、 256 點訊號,則頻譜總共 256 種頻率。第一種頻率是 0Hz ,接著每一種頻率相差 48000Hz / 256 = 187.5Hz 。前 128 種、後 128 種左右對稱,後 128 種沒有實際作用。呼應取樣定理,資訊量只剩一半
spectrogram 頻譜圖:所有時間點的頻率分佈圖。
Window
原本完整的聲音波形,硬生生被框截斷,頻譜將產生誤差。解法:將框的兩端的訊號漸漸減弱,減少影響。也就是乘上一個中央高、兩側低的函數,數值皆介於零到一之間,稱作「窗函數 Window Function 」。

Filter 濾波器
頻譜是分析聲音的工具。濾波器則是修改聲音的工具。例如刪除聲音的高頻部分,稱做 lowpass filter 。
濾波器有時域與頻域兩大類。
時域濾波器,直接的修改訊號。計算速度飛快,但是需要「數位訊號處理」的數學知識。例如 shelving filter 。
頻域濾波器,間接的修改頻譜。原訊號 FFT 得到頻譜,修改頻譜(例如把低頻的強度和相位調成 0 ,形成 highpass filter ),再 IFFT 得到新訊號。

peak detection
找到波形的尖峰。

消除鋸齒:方法很多,諸如 * 時域的平滑效果(k點平均值)(k點中位數)。 * 頻域的刪除高頻(高頻形成鋸齒)。 * 時域的Linear Prediction(迴歸函數)。
frequency detection
找到波形的頻率。

時域的方法 peak detection:找到兩個波峰,位置相減得到波長,波長倒數得到頻率。僅適合純音。 zero-crossing rate:波形穿越零的次數。僅適合純音。 ACF:位移、相乘、加總(內積)。各種位移量,找最大值。 AMDF:位移、相減再絕對值、加總(絕對值誤差)。各種位移量,找最小值。 YIN:位移、相減再平方、加總(平方誤差)。各種位移量,除以前綴和,找最小值。 複合:例如 ACF / (AMDF + 1.0),找最大值。
頻域的方法 peak detection:找到強度最高的頻率。計算速度較慢。
語音處理
gain :音量放大(縮小)。振幅乘上倍率。波形於垂直方向伸展或壓扁。
normalization :校準聲音波形,中央為 0 ,最高振幅為 1 。等同於聲音儘量調到最大聲。
pre-emphasis :有時候錄音環境不佳,錄製到的聲音濛濛霧霧。微分運算可使聲音清晰。副作用是音量下降。
smoothing :有時候錄音環境不佳,錄製到的聲音唧唧吱吱。平均值可抑制雜訊。副作用是聲音模糊不清、音量下降。
mixing :混音。混和好幾道聲音。其實就是加權平均值。
echo :回聲。相同聲音稍後再度出現。其實就是延遲與混音(位移與疊加)。
reverb :迴響。餘音繞樑。反覆回音,間隔極短。聽起來彷彿位於寬敞的密閉空間。
pitch shifting :移調。改變頻率。
chorus :合唱。混和好幾道聲音,每道聲音的頻率略有變動、延遲時間略有差異。
robot sound :簡易做法是混和兩道聲音,頻率略高、頻率略低的聲音。
harmonics :和聲。混和好幾道聲音,每道聲音的頻率皆不同。
distortion :失真。降低聲音品質,聽起來像破音。
equalization :調整每個頻帶的音量,使得聽起來均勻。套用許多個濾波器即可。
pitch bending :轉音。頻率平滑地增減(頻譜的強度平滑地位移)。
morphing :一種聲音,平滑柔順地轉化成另一種聲音。推測是每個頻帶各自轉音。
Fourier transform
聲音訊號可分解為不同振幅、頻率、相位的波覆蓋。波的相位可用複數表示。
離散傅立葉轉換 DFT 是一個將 n 個複數的向量,對應到 n 個複數的另一個向量的函數。
\(X(k)=\sum_{t=0}^{N-1} x(t) e^{-i2 \pi \frac{tk}{N}}, k=0, ..., N-1\)
向量 x 是個時間點的訊號水平
向量 X 是個頻率下的訊號水平
這個公式的意思是,在頻率 k 處的訊號水平等於每個時間 t 的訊號水平 * 複數指數的總和
尤拉公式: 對任意實數 x : \( e^{xi} = cosx + i sinx \)
cos 是偶函數,因此 \( cos(-x) = cosx\)
sin 是奇函數,因此 \( sin(-x)=-sinx\)
\( e^{-i2 \pi \frac{tk}{N}} = e^{(-2 \pi \frac{tk}{N})i} = cos(-2\pi \frac{tk}{N}) + i sin(-2 \pi \frac{tk}{N}) = cos(2\pi \frac{tk}{N}) - i sin(2 \pi \frac{tk}{N}) \)
\( x= Re(x) + i Im(x)\) Re: 實部 Im: 虛部
\( x(t) e^{-i2 \pi \frac{tk}{N}} = [Re(x(t)) + i Im(x(t))][cos(2\pi \frac{tk}{N}) - i sin(2 \pi \frac{tk}{N})]\)
兩個複數相乘
\( x(t) e^{-i2 \pi \frac{tk}{N}} = [Re(x(t))cos(2\pi \frac{tk}{N}) + Im(x(t))sin(2 \pi \frac{tk}{N})] + i[-Re(x(t))sin(2 \pi \frac{tk}{N}) + Im(x(t)) cos(2 \pi \frac{tk}{N})]\)
N 個波,頻率是 0 倍、 0.5 倍、 1 倍、 1.5 倍、 …… ,分別是 cos((2π/N)⋅0⋅t) 、 cos((2π/N)⋅0.5⋅t) 、 cos((2π/N)⋅1⋅t) 、 …… 。寫成代數是 cos((2π/N)⋅(f/2)⋅t) 。
輸入數列與一個波,置中對齊。 N 個對應位置,相乘後求和(點積),得到一個輸出數值。
輸入數列,分別投影至 N 個波,得到 N 個輸出數值,形成輸出數列。這就是餘弦轉換。
正向餘弦轉換:一個複雜的波,拆解成 N 個平穩的波,頻率是 0 倍開始漸增 0.5 倍,振幅是 N 個輸出數值,相位都是 0 。
逆向餘弦轉換: N 個平穩的波,頻率是 0 倍開始漸增 0.5 倍,分別乘上振幅,疊加成一個複雜的波。
DFT 時間複雜度為 O(n^2)
1965 提出了一個 Cooley-Turkey Fast Fourier 演算法,以 divide-and-conquer 為方法,遞迴地將長度 \(N=N_1N_2\) 的 DST 轉換分解為長度 \(N_1\) 的 \(N_2\) 個較短序列的 DST,以及 O(N) 個旋轉因數的複數乘法
MFCC 特徵
- 輸入 16kHz 音訊
- 以 25ms 的 window,每次移動 10ms 輸出一個向量數列,產生數值數列
- 乘上 windows 函數 (ex: 漢明距離)
- 執行 FFT
- 在每個頻率桶中記錄能量,也就是計算每個頻率區間的能量
- 執行 DCT 離散餘弦轉換,得到 「倒譜」
- 保留倒譜的前 13 個係數
深度學習可直接使用聲音的 wav file,不使用 MFCC
說話特徵
不同 speaker 在一個通用聲學簇內具有不同的子空間。
由通用簇偏移的子空間,描述了樣本的方向向量,取決於說話者的語言文字。
為取得相關的(含說話者) 的特徵,將這些向量分析為特徵因數。分析的因數特徵稱為身份向量 (identity vectors: I-vectors)。 i-vectors 就是說話者的特徵,可用來辨識說話者。(ex: 利用兩個語音向量的餘弦距離,作為兩段語音是否來自同一個說話者的衡量指標)
解碼
kaldi 工具中,沒有單一標準解碼器,或滿足固定介面的解碼器
目前有 SimpleDecoder 與 FasterDecoder 解碼器,及詞圖產生解碼器。有 command line tool 封裝這些解碼器,他們可解碼特定類型的模型 (ex: GMM) 或具有特定的特殊條件 (ex: 多類別 fMLLR)
解碼的 command 為 gmm-decode-simple, gmm-decode-faster, gem-decode-kaldi, gmm-decode-faster-fmllr。目前不提供可執行所有可能類型的解碼指令
語言模型
語音辨識是使用語言模型解碼識別結果。以下是 機率語言模型 & 語言模型套件 KenLM
機率語言模型
輸入語音序列 「已經還了」
兩種辨識結果,要如何評價?
\(S_1\) 已經/還/了
\(S_2\) 已經/黃/了
根據條件機率 \(P(S_1|C), P(S_2|C)\) 的值決定選擇哪一個
貝氏定理 \(P(C∩S) = P(S|C)P(C)=P(C|S)P(S)\) -> \(P(S|C) = \frac{P(C|S)P(S)}{P(C)}\)
\(P(C)\) 是字串在語料庫中出現的機率。 ex: 語料庫有一萬個句子,其中一句:「生命的意義是什麼」,\(P(C)=P("生命的意義是什麼")=0.0001\) 。
因字串恢復到中文字串的機率只有唯一一種,所以 \(P(C|S)=1\)
比較 \(P(S_1|C), P(S_2|C)\) 的大小,變成比較 \(P(S_1), P(S_2)\) 的大小,因為 \(\frac{P(S_1|C)}{P(S_2)|C} = \frac {P(S_1)}{P(S_2)}\)
\(P(S_1 已經/還/了) > P(S_2 已經/黃/了)\) 所以選擇 \(S_1\)
機率語言模型是用來評估指定詞序列 S 的機率 P(S),為簡化計算,假設每個詞之間的機率跟上下文無關
\(P(S)=P(w_1, w_2, .... w_r) = P(w_1)P(w_2)...P(w_r)\) 其中 \(P(w)\) 是詞 w 出現在語料庫中的機率
ex: \( P(S_1 已經/還/了) = P(已經) P(還) P(了)\)
因為詞表中的詞很多,分配到一個詞的機率很小,所以 \(P(S)\) 會是很多很小的數值的乘積。因此利用對數 \(y=log(x)\) 進行轉換,取對數後,表示一個小於 1 的正數的精確度加強了
\(P(S) = P(w_1)P(w_2)...P(w_r) => logP(w_1) logP(w_2)... logP(w_r)\)
因為機率小於 1 ,取對數後是負數
計算任一個詞出現的機率為 \(P(w_1) = \frac {w_1在語料庫出現的次數 n}{語料庫的總詞數 N}\) ,因此 \( logP(w_1) = log(freq_w) - logN\)
如果已經先算出詞機率的對數值,結果可直接用加法,得到 \(logP(S)\)
這個 \(P(S)\) 公式,就是一元機率語言模型為基礎的計算公式
一元模型
假設語料庫有 10000 個詞,其中 「了」出現了 180 次,則機率為 0.018
| 詞語 | 詞頻 | 概率 |
|---|---|---|
| 了 | 180 | 0.0180 |
| 還 | 5 | 0.0005 |
| 已經 | 10 | 0.0010 |
| 黃 | 2 | 0.0002 |
\(P(S_1) = P(已經)P(還)P(了) = 0.001*0.0005*0.018 = 9*10^{-9}\)
\(P(S_2) = P(已經)P(黃)P(了) = 0.001*0.0002*0.018 = 3.6*10^{-9}\)
因為 \(P(S_1) > P(S_2)\) 故選擇 \(S_1\)
取對數的計算:
\(logP(S_1) = logP(已經)logP(還)logP(了) = -18.52604\)
\(logP(S_2) = logP(已經)logP(黃)logP(了) = -19.44233199\)
結果一樣 \(logP(S_1) > logP(S_2)\)
資料基礎
機率語言需要知道哪些是高頻詞,哪些是低頻詞,也就是
\(P(w) = \frac {freq(w)}{所有詞的總次數}\)
詞語機率表是由語料庫統計出來的。為支援中文分詞方法,需要增加分詞資料庫
從分詞語料庫加工出人工可以編輯的一元詞典。一元的英文是 Unigram,一元詞典就稱為 UnigramDic
UnigramDic.txt sample:
有: 180
有意: 5
意見: 10
見: 2
分歧: 1
大學生: 139
生活: 1671可根據 UnigramDic.txt 產生一元詞典樹

為快速產生詞典樹,可把結構儲存下來。
以 Depth First 方式,對每個節點編號,沒有孩子的分支節點編號為 -1。根據編號,以 節點編號#左邊孩子節點的編號#中間孩子節點的編號#右邊孩子節點的編號#節點本身的資料 的格式,儲存節點之間的關係資料。
0#1#2#3#有
1#4#5#6#基
2#7#8#9#道改進一元模型
計算最佳前驅節點到目前節點的傳輸機率,考慮更前面的切分路徑。
以 \(P(w_i|w_{i-1})\) 的值代替 \(P(W_i)\)
如果用最大似然估計 \(P(w_i|w_{i-1})\) ,則 \(P(w_i|w_{i-1}) = \frac {freq(w_{i-1}, w_i)}{freq(w_{i-1})}\)
ex: \(freq(有,意見) = 4\),則 \(P(意見|有) = freq(有, 意見)/freq(有) = 4/4000 = 0.001\)
ex: 語料庫中存在 「北京/舉行/新年/音樂會」,就存在了一元連結。存在二元連結:北京@舉行, 舉行@新年, 新年@音樂會。
可從語料庫統計前後兩個詞一起出現的次數
如果 「意見, 分歧」 沒找到其他搭配的詞, \(P(S_1), P(S_2)\) 都是 0,無法透過比較計算結果,找到更好的切分方案,這是零機率問題。
使用 \(freq(w_{i-1}, w_i)/freq(w_{i-1})\) 估計 \(P(w_i|w_{i-1})\)
使用 \(freq(w_{i-2}, w_{i-1}, w_i)/freq(w_{i-2}, w_{i-1})\) 估計 \(P(w_i|w_{i-2}, w_{i-1})\)
因為使用了最大似然估計法,所以把 \(freq(w_{i-1}, w_i)/freq(w_{i-1})\) 稱為 \(P_{ML}(w_i|w_{i-1})\)
\(P_{l_i}(w_i|w_{i-1}) = 𝜆_1 P_{ML}(w_i) + 𝜆_2 P_{ML}(w_i|w_{i-1}) = 𝜆_1(freq(w_i)/N) + 𝜆_2(freq(w_{i-1}, w_i) / freq(w_{i-1}))\)
對於 \(P_{l_i}(w_i|w_{i-2}, w_{i-1})\) 則是
\(P_{l_i}(w_i|w_{i-2}, w_{i-1}) = 𝜆_1 P_{ML}(w_i) + 𝜆_2 P_{ML}(w_i|w_{i-1}) + + 𝜆_3 P_{ML}(w_i|w_{i-2}, w_{i-1}) \)
其中 \(l_1 + l_2 + l_3 = 1\)
根據平滑公式計算,由於 \(P'(w_i|w_{i-1}) = 0.3 P(w_i) + 0.7 P(w_i | w_{i-1})\)
所以
\( P(S_1) = P(有) P'(意見|有) P'(分歧|意見) \\ = P(有)*(0.3 P(意見)+0.7P(意見|有)) * (0.3P(分歧)+0.7 P(分歧|意見)) \\ = 0.0180*(0.3*0.001+0.7*0.001)*(0.3*0.0001) \\ = 5.4*10^{-9} \)
\( P(S_2) = P(有意) P'(見|有意) P'(分歧|見) \\ = P(有意)*(0.3 P(見)+0.7P(見|有意)) * (0.3P(分歧)+0.7 P(分歧|見)) \\ = 0.0005*(0.3*0.0002)*(0.3*0.0001) \\ = 9*10^{-13} \)
\(P(S_1) > P(S_2)\) 改進一元模型,結果的區分度比較好
二元詞典
也就是 BigramDic,其中 "0START.0" "0END.0" 是虛擬的開始, 結束詞語
ex:
0START.0@歡迎 -> 「歡迎」 是開始詞
什麼@0END.0 -> 「什麼」是結束詞二元詞表格式為 「前一個詞@後一個詞」組合出現的次數
中國@北京:100
中國@北海:1二元詞表會有幾十萬筆,要考慮如何快速查詢
要先載入一元詞典,建置詞典樹結構,再載入二元詞典,也就是在詞典樹的結構,加掛上二元連結資訊。

N元模型
一元詞典假設兩個詞出現的機率互相獨立,但實際上不可能。
N元模型用 n 個單字組成的序列衡量切分方案的合理性
但當詞數有 20000,二元組合就有 20000^2 個,三元組合有 20000^3 個
利用馬可夫假設,解決參數空間過大的問題
馬可夫假設:一個詞的出現,僅依賴於前面出現的有限的幾個詞。
如果一個詞的出現,僅依賴於前面出現的一個詞,也就是二元模型 ex: \(P(S_1)=P(有) P(意見|有) P(分歧|意見)\)
如果一個詞的出現,僅依賴於前面出現的2個詞,就是三元模型
如果切分方案 S 由 n 個片語組成, \(P(w_1)P(w_2|w_1)P(w_3|w_2) ... P(w_n|w_{n-1})\),也就是 n 項連乘積
ex: Bigram \(P(S_1)=P(有) P(意見|有) P(分歧|意見)\)
Trigram \(P(S_1)=P(有) P(意見|有) P(分歧|有,意見)\)
因為 \(P(w_i|w_{i-1}) = freq(w_{i-1}, w_i)/freq(w_{i-1})\) 二元分詞也要使用到一元詞典
n 元機率 https://github.com/esbie/ngrams
評估語言模型
透過困惑度 perplexity 衡量語言模型。
困惑度 perplexity 是一個語言事件的不確定性的度量。
ex: 「行」後面可接 「走」「善」「不行」,所以「行」的困惑度高
有些詞的困惑度低
語言模型的困惑度要越低越好,這樣會有比較強的消除問題的能力。專業領域的語料庫,會有比較低的困惑度
困惑度的定義:
假設有一些測試資料,n個句子:\(S_1, S_2,... S_n\) 整個測試集 T 的機率為
\(log \sum_{i=1}^{n}P(S_i) = \sum_{i=1}^{n} logP(S_i)\)
困惑度為 \(2^{-x}\) 其中 \(x=\frac{1}{W} \sum_{i=1}^{n} logP(S_i)\) , W 是測試集 T 的總詞數
假設詞表 V,其中有 N 個詞。 \(P(w)=1/N\) 困惑度為 \(2^{-x}\) ,其中 \(x=log(1/N)\) ,所以困惑度為 N
ex:
訓練集有 38000 萬個詞,詞表有 19979 個詞,測試集有 150萬個詞。一元模型的困惑度 = 962
二元模型困惑度 = 170,三元模型困惑度 = 109
平滑演算法
語料有限,不可能覆蓋所有詞彙,當 N 元模型,N很大時,由於樣本數量有限,導致先驗機率值為 0,這就是 零機率問題。
當 N=1 一元模型,也存在零機率問題。例如有些詞在詞表中,但沒有出現在語料庫。
回歸分析可用來預測沒有測量過的值。
平滑演算法就是用觀測到的事件,預測未觀測事件的機率。
資料稀疏在統計自然語言處理中表現的就是零機率問題。有各種平滑演算法可解決此問題
最簡單的是加法平滑演算法。原理是替每個專案增加 \(lambda\) ( 其中 \(1>=lambda>=0\)) ,然後除以總數,作為專案新的機率。因數學家 Laplace 首先提出用加 1 的方法,估計沒有出現過的現象的機率,所以加法平滑也稱為 Laplace平滑
因不容易決定 lambda 的值。另一種 Good-Turning 方法不需要 lambda
假設詞典有 x 個詞,在語料庫出現 r 次的詞有 \(N_r\) 個,例如出現一次有 \(N_1\) 個
語料庫總詞數 \(N=0*N_0 + 1*N_1 + ... + r*N_r\) 其中 \(x=N_0+N_1+.. +N_r\)
使用觀察到的類別 r+1 的全部機率,估計類別 r 的全部機率。
沒有出現過的詞的總機率 \(p_0 = N_1/N\) 分攤到每個詞的機率為 \(N_1/(N*N_0)\)
第二步是估計語料庫中,出現過一次的總機率為 \(p_1 = 2N_2/N\) 分攤到每個詞的機率為 \(N_2/(N*N_1)\)
當 r 很大, \(N_r\) 可能為 0,此時不再求平滑

對條件機率的 N 元估計平滑
\(P_{GT}(w_i|w_1,...,w_{i-1}) = \frac{c^*(w_1,...,w_i)}{c^*(w_1,...,w_{i-1})}\)
其中 \(c^*\) 就是 GT 估計
估計三元條件機率為 \(P_{GT}(w_3|w_1,w_2) = \frac{c^*(w_1,w_2,w_3)}{c^*(w_1,w_2)}\)
對沒出現詞語的三元聯合機率為
\(P_{GT}(w_1,w_2,w_3) = C_0^*/N = N_1/(N_0*N)\)
KenLM 語言模型工具
github: https://github.com/kpu/kenlm.git
python module: pip install https://github.com/kpu/kenlm/archive/master.zip
測試語言模型檔案 test.arpa
使用 test.arpa 評估句子的機率
import kenlm
model = kenlm.Model('lm/test.arpa')
print(model.score('this is a sentence .', bos = True, eos = True))
#輸出
-49.57345703125kenlm 編譯後可使用修改的 Kerser-Ney 平滑法從輸入文字 test.arpa 估計語言模型
$bin/lmplz -o 5 <test > text.arpa建立三元模型
./lmplz --order 3 --text input.txt.tok --arpa output.arpaARPA 檔案格式
n-gram 語言模型格式
<LM_definition> = [ { <comment> } ]
\data\
<header>
<body>
\end\
<comment> = { <word> }<header> = { ngram <int>=<int> }其中 第一個
<body> = { <lmpart1> } <lmpart2>
<lmpart1> = \<int>-grams:
{ <ngramdef1> }
<lmpart2> = \<int>-grams:
{ <ngramdef2> }
<ngramdef1> = <float> { <word> } <float>
<ngramdef2> = <float> { <word> }bigram 語言模型由 unigram 與 bigram 兩個部分組成。
實際機率用對數取代,所以會看到負數
sample:
wood pittsburgh cindy jean
jean wood共四個單字,加上 句子開始 <s>、結束 </s>、未知單字 <unk> ,共七個
語言模型:
\data\
ngram 1=7
ngram 2=7
\1-grams:
-1.0000 <unk> -0.2553
-98.9366 <s> -0.3064
-1.0000 </s> 0.0000
-0.6990 wood -0.2553
-0.6990 cindy -0.2553
-0.6990 pittsburgh -0.2553
-0.6990 jean -0.1973
\2-grams:
-0.2553 <unk> wood
-0.2553 <s> <unk>
-0.2553 wood pittsburgh
-0.2553 cindy jean
-0.2553 pittsburgh cindy
-0.5563 jean </s>
-0.5563 jean wood
\end\依存語言模型
可建立單字之間的句法相依關係模型。
詞之間的關係有方向性。大多數的語言都滿足投射性,也就是如果 詞 p 依存於 詞 q,那麼 p 和 q 之間的任意詞 r 就不能依存到 p 和 q 組成的跨度之外。

箭頭的起點是從屬詞(修飾詞),終點指向支配詞(核心詞),弧上標記是依存關係標記。
一:從屬詞,本:支配詞,"qc" 是依存關係標記
依存文法也可以表示成樹狀結構

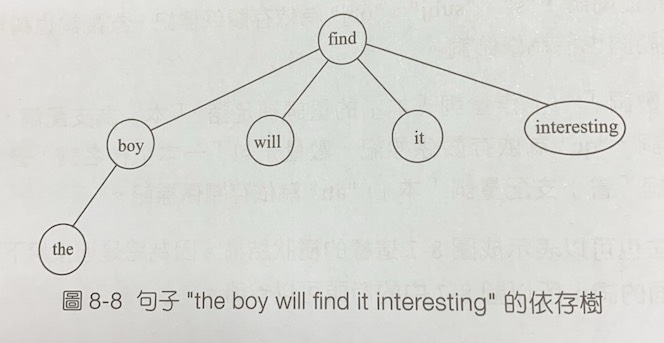
機率計算公式: T: 依存樹拓樸關係
\( P(s|T) = P(the|boy) P(boy|find) P(will|find) P(find|<NONE>) P(it|find) P(interesting|find) \)
References
Tutorials
The CMU Pronouncing Dictionary.
- 聲學模型:是將聲學和發音學(phonetics)的知識進行整合,以特徵提取部分生成的特徵作為輸入,並為可變長特徵序列生成聲學模型分數。
- 語言模型:通過從訓練語料(通常是文本形式)學習詞之間的相互關係,來估計假設詞序列的可能性,又叫語言模型分數。
- GMM:Gaussian Mixture Model, 高斯混合模型,描述基於傅里葉頻譜語音特徵的統計模型,用於傳統聲學模型的建模中。
- HMM:Hidden Markov Model, 隱馬爾科夫模型,是一種用來描述含有隱含未知參數的馬爾科夫過程,其難點是從可觀察的參數中確定該過程的隱含參數。然後利用這些參數來作進一步的分析,例如模式識別。
- MFCC:Mel-Frequency Cepstral Coefficients, 梅爾頻率倒譜係數,是組成梅爾頻率倒譜的係數。衍生自音訊片段的倒頻譜(cepstrum)。倒譜與梅爾頻率倒譜的區別在於,梅爾頻率倒譜的頻帶劃分是在梅爾刻度上等距劃分的,它比用於正常的對數倒頻譜中的線性間隔的頻帶更接近人類的聽覺系統。廣泛應用於語音識別中。
- Fbank:Mel Frequency Filter Bank, 梅爾頻率濾波器組。
- WER:Word Error Rate, 詞錯誤率,是最常見的衡量語音識別系統性能的指標。

- 特徵提取:語音識別第一步就是特徵提取,去除掉語音信號中對於語音識別無用的冗餘信息(如背景噪音),保留能夠反映語音本質特徵的信息(為後面的聲學模型提取合適的特徵向量),並用一定的形式表示出來;較常用的特徵提取算法有 MFCC。
- 聲學模型訓練:根據語音庫的特徵參數訓練出聲學模型參數,在識別的時候可以將待識別的語音的特徵參數同聲學模型進行匹配,從而得到識別結果。目前主流的語音識別系統多採用 HMM 進行聲學模型建模。
- 語言模型訓練:就是用來計算一個句子出現的概率模型,主要用於決定哪個詞序列的可能性更大。語言模型分為三個層次:字典知識、語法知識、句法知識。對訓練文本庫進行語法、語義分析,經過基於統計模型訓練得到語言模型。
- 語音解碼與搜索算法:其中解碼器就是針對輸入的語音信號,根據已經訓練好的聲學模型、語言模型以及字典建立一個識別網絡,再根據搜索算法在該網絡中尋找一條最佳路徑,使得能夠以最大概率輸出該語音信號的詞串,這樣就確定這個語音樣本的文字。
語音識別工具包Kaldi的學習和使用(三):數據集的訓練和使用
語音識別大牛 Daniel Povey 莫名被JHU開除後,怒拒Facebook,轉向中國公司與高校
中文是一個有音調的語言,音調對字和詞的識別是有影響的。音調信息如果用好的話,就有可能提升識別率。不過大家發現 deep learning 模型有很強的非線性映射功能,很多音調裡的信息可以被模型自動學到,不需要特別處理。
很多研究組都發現或證實使用小 Kernel 的 Deep CNN 比我們之前在書裡面提到的使用大 kernel 的 CNN 方法效果更好。Deep CNN 跟 LSTM 比有一個好處。用 LSTM 的話,一般你需要用雙向的 LSTM 效果才比較好。但是雙向 LSTM 會引入很長的時延,因為必須要在整個句子說完之後,識別才能開始。而 Deep CNN 的時延相對短很多,所以在實時系統裡面我們會更傾向於用 Deep CNN 而不是雙向 LSTM。
System architecture of the cloud-based HALEF spoken dialog system depicting the various modular open-source components

Kaldi 是一個非常強大的語音識別工具庫,最近有些業者用 kaldi nnet3 語音辨識工具進行 TDNN 訓練,用於機器人電話客服。
語音變成文字的大致流程為:將一段語音的聲波按幀切開,用幀組成狀態,用狀態組成音素,再將音素合成單詞,語音就變成了文字 。
學習kaldi的話,先從hmm-gmm入手比較好,像steps/traindelta.sh, steps/trainfmllr.sh, steps/decode.sh這些腳本都是基於hmm-gmm模型。
搞清楚hmm-gmm之後對語音識別就有了一個清晰的理解,接下來就可以上手神經網絡。kaldi支持很多神經網路,如MLP, RNN, CNN, LSTM,如果對神經網路瞭解不多還是從MLP入手較好,MLP是神經網路中最基礎的模型。
book
GitHub projects
zzw922cn/AutomaticSpeechRecognition
End-to-end Automatic Speech Recognition for Madarian and English in Tensorflow
A Chinese Deep Speech Recognition System 包括基於深度學習的聲學模型和基於深度學習的語言模型
基於深度學習的中文語音識別系統
中文語音識別,高識別率預訓練模型,支持docker快速安裝 Chinese Speech Recognition; Mandarin Automatic Speech Recognition;
An very convenient Audio Recorder For ASR Projects. It can recording 16K 16Bit Wav files for ASR projects for the next recognizing. it use directsound for recording in Windows OS , Python3.6 . Press Enter to start recording , and press Enter again to stop recording as you think it's recording enough. Press 'q' to exit the process.
沒有留言:
張貼留言