
有許多自然或社會現象,其發展或演變會隨時間進行而呈現出幾種可能的狀態,稱為狀態空間,這種隨機變化的過程稱為隨機過程 stochastic process。如果記錄狀態的時間點是離散的,就稱為離散時間隨機過程, Markov Process 或是高速公路每天的意外事件數量就是一種離散時間隨機過程,如果記錄狀態的時間點是連續的,就稱為連續時間隨機過程,布朗運動 Brownian Motion 或是在銀行等待服務的人數就是一種連續時間隨機過程。
如果時間與狀態都是離散的 Markov Process 就稱為 Markov Chain。Markov Chain 是隨機變數 \(X_0, X_1, X_2, X_3, ...\) ,也就是 \({X_n, n>=0}\) 的一個數列,其中 \(X_0, X_1, ... X_{n-1}\) 都是過去時間的狀態, \(X_n\) 是目前的狀態, \(X_{n+1}, X_{n+2}, ...\) 是未來的狀態,每一個狀態可轉移到其他狀態,轉移的機率總和為 1,因此目前的狀態都是由前一個狀態以及轉移機率來決定的。
討論 Markov Chain 有兩個先決條件
- 目前的狀態都是由前一個狀態的轉移機率來決定的
- 在任何時間點,系統的事件只存在於某一種狀態中
Makov Chain 的表示方式
transition diagram

transition matrix 轉移矩陣
\( \begin{bmatrix} 0 & 1 & 0 \\ 0 & 0.5 & 0.5 \\ 0.6 & 0 & 0.4 \end{bmatrix} \)
tree diagram


transition matrix
為方便計算,以 transition matrix 作為表示方式
\( T = \begin{bmatrix} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \\ a_{31} & a_{32} & a_{33} \end{bmatrix} \)
選定某一個狀態為起點,根據轉移矩陣改變狀態,當狀態不斷地改變,會產生一個狀態變化的路徑。如考慮所有的狀況,可計算出每一個路徑的發生機率,這些路徑就稱為 Markov Chain。
問題:如果一開始的狀態在 \(a_1\) ,三天後,在 \(a_2\) 的機率為?
一天後: \( \begin{bmatrix} 1 & 0 & 0 \end{bmatrix}\begin{bmatrix} 0 & 1 & 0 \\ 0 & 0.5 & 0.5 \\ 0.6 & 0 & 0.4 \end{bmatrix} = \begin{bmatrix} 0 & 1 & 0 \end{bmatrix} \)
兩天後: \( \begin{bmatrix} 0 & 1 & 0 \end{bmatrix}\begin{bmatrix} 0 & 1 & 0 \\ 0 & 0.5 & 0.5 \\ 0.6 & 0 & 0.4 \end{bmatrix} = \begin{bmatrix} 0 & 0.5 & 0.5 \end{bmatrix} \)
三天後: \( \begin{bmatrix} 0 & 0.5 & 0.5 \end{bmatrix}\begin{bmatrix} 0 & 1 & 0 \\ 0 & 0.5 & 0.5 \\ 0.6 & 0 & 0.4 \end{bmatrix} = \begin{bmatrix} 0.3 & 0.25 & 0.45 \end{bmatrix} \)
如果直接一次計算:\( \begin{bmatrix} 1 & 0 & 0 \end{bmatrix} T^3 = \begin{bmatrix} 1 & 0 & 0 \end{bmatrix}(\begin{bmatrix} 0 & 1 & 0 \\ 0 & 0.5 & 0.5 \\ 0.6 & 0 & 0.4 \end{bmatrix})^3 = \begin{bmatrix} 0.3 & 0.25 & 0.45 \end{bmatrix} \)
結果為 0.25
吸收馬可夫鏈
在 Markov Process 中,當事件進入某個狀態時,就一直停留在該狀態,稱該狀態為吸收狀態 absorbing state
如果 Markov Chain 有下列兩種特性,就稱為 Absorbing Markov Chain
- 至少存在一個吸收狀態
- 事件在任何非吸收狀態時,經過有限時間後,就會進入 absorbing state
ex:
\( \begin{bmatrix} 0.2 & 0.3 & 0 & 0.5 \\ 0 & 0.4 & 0 & 0.6 \\ 0.5 & 0 & 0.5 & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix} \) 是一種 Absorbing Markov Chain
\( \begin{bmatrix} 0.2 & 0 & 0.4 & 0.4 \\ 0 & 1 & 0 & 0 \\ 0.1 & 0 & 0.5 & 0.4 \\ 0.5 & 0 & 0.3 & 0.2 \end{bmatrix} \) 不是一種 Absorbing Markov Chain,雖然 \(a_2\) 是 absorbing state,但是其他三種狀態,都不能到達 \(a_2\),因此這不是 Absorbing Markov Chain
醫院是一種 absorbing markov chain 的實例,如果將進入醫院住院的病患,分為住院可走動,住院臥床,痊癒出院,死亡四種狀態,這四種狀態可以構成一個 absorbing markov chain,其中痊癒出院即死亡,都分別為 absorbing state
工廠品管商品,生產線製造的新品(狀態1),通過品管後為合格品(狀態2),失敗的商品會進入再造品(狀態3),再造品可再重新加工,變成修復品(狀態4),重新加工失敗最終成為報廢品(狀態5)
\( \begin{matrix} \begin{matrix} \quad\quad\quad\quad & 合格品 & 報廢品 & 新品 & 再造品 & 修復品 \end{matrix} \\ \begin{matrix} 合格品 \\ 報廢品 \\ 新品 \\ 再造品 \\ 修復品 \end{matrix} \begin{bmatrix} 1 & 0 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 & 0 \\ 0.7 & 0 & 0 & 0.3 & 0 \\ 0.9 & 0 & 0 & 0 & 0.1 \\ 0.6 & 0.4 & 0 & 0 & 0 \end{bmatrix} \end{matrix} \)
m 階馬可夫鏈
前面討論的 Markov Chain,用前一個單位時間的狀態可以預測下一個狀態,這稱為一階馬可夫鏈 first-order Markov Chain,如果需要前 m 個狀態,才能預測下一個狀態,就稱為 m 階馬可夫鏈。當然也有零階馬可夫鏈,也就是一般的機率分佈模型。
通常討論的馬可夫鏈都是一階馬可夫鏈,最重要的是無記憶性,因為系統不需要記錄前面經過的狀態,只需要目前的狀態,就可以預測下一個狀態。
HMM: Hidden Markov Model
當系統存在一些外部看不見的內部狀態,隨著系統內部狀態不同,表現出來的外部狀態也不同,我們可以直接觀察到外部狀態。
以買飲料為例,假設目前有三種飲料可以選擇:可樂、茶、牛奶,我們只能觀察到使用者每天早上9:00吃早餐,正在喝哪一種飲料,但是我們不知道他今天是在 7-11、FamilyMart 或是 HiLife 買到的。便利商店是內部狀態,三種飲料是外部狀態。

內部狀態的變化可用一個 transition matrix 表示
\( A= \begin{bmatrix} 0.7 & 0.1 & 0.2 \\ 0.3 & 0.2 & 0.5 \\ 0.4 & 0.3 & 0.3 \end{bmatrix} \)
不同的內部狀態,會產生不同的外部狀態,也可以用另一個 matrix 表示
\( B = \begin{bmatrix} 0.2 & 0.2 & 0.6 \\ 0.3 & 0.3 & 0.4 \\ 0.5 & 0.3 & 0.2 \end{bmatrix} \)
如果以 h 為內部狀態, \(h^{t}\) 為 t 單位時間的內部狀態, y 為外部狀態,\(y^{t}\) 是 t 單位時間的外部狀態,則
\(h^{t} = h^{t-1}A\)
\(y^{t} = h^{t}B\)

在實務上的問題,我們只知道外部狀態的觀察值,內部狀態被隱藏無法得知,也就是我們不會知道 transition matrix 實際的機率值,也就是我們不知道 A 與 B 的數值,只有一堆數據資料。
例如我們目前有甲乙丙三個人半年來每一週買飲料的歷史資料,當給定某一週買飲料的序列清單時,我們可以根據歷史資料,找出每一個人的購買習慣,也就是計算出 transition matrix,訓練模型,最後利用這個模型,將新的那一週的資料,分類判斷可能是哪一個人購買的。
在已知觀察序列,但未知轉移矩陣的條件下,找出其對應的的所有可能狀態序列,以及其中最大機率之狀態序列。
HMM 是有關時間序列的數據資料建立的模型,也是所有時間模型(ex: RNN, NLP, RL)的基礎。
HMM 三個基本問題
定義HMM參數為 λ,S 為狀態值集合, O 為觀察值集合,初始機率 π (Initial Probability)、轉移機率 A (Transition Probability)、發射機率 B (Emission Probability),因此 λ = ( π, A, B )
Evaluation Problem
評估問題最簡單,將所有機率做乘積就可以得到觀測序列發生的機率。
根據觀察序列O及已知的模型參數λ,得出發生此序列的機率 P(O|λ)
可用 Forward-backward Algorithm 降低計算複雜度
Decoding Problem
根據觀察序列O及模型參數λ,得出最有可能的隱藏狀態序列(hidden state sequence),也就是要求得哪一種狀態序列發生的機率最大,求給定觀測序列條件概率P(I|Q,λ)最大的狀態序列I
可用 Viterbi Algorithm
Viterbi算法是求最短路徑的過程,由於不知道每個觀測狀態的隱藏狀態是什麼,所以初始化時,每種隱藏狀態都有可能,計算在每種隱藏狀態下的整個觀測序列發生的機率,機率最大的那條路徑就是每個觀測狀態對應的唯一隱藏狀態。
Learning Problem
學習問題最複雜
在已知隱藏狀態與觀察狀態的條件下,根據觀察序列O,找到最佳的參數 狀態轉移矩陣 A、觀察轉移矩陣 B、起始值機率 π,調整模型參數 λ = [A, B, π] 使得 P(O|λ) 最大化
可用 EM Algorithm
語音辨識 HMM
語音辨識的目標,是事先使用大量語料,對每一個辨識語句建立一個 DHMM,然後當我們取得使用者輸入的測試語句後,即對測試語句進行端點偵測及 MFCC 特徵擷取,然後再將 MFCC 送至各個辨識語句所形成的 DHMM,算出每一個模型的機率值,機率值最大的 DHMM,所對應的辨識語句就是此系統的辨識結果。每一個音框的特徵向量都是39維的 MFCC
建立 0~9 數字語音辨識的方法
- 建立 0, 1, 2 ~ 9 的 HMMs
- 利用 Viterbi Decoding 找到新語句中,計算針對每一個 HMM 發音音素順序的序列的發生機率,也就是計算輸入語句和每個模型的相似度
- 最大機率值的 HMM,就是預測的 digit
進行 DHMM 的設計時,我們必須對每一個數字建立一個 HMM 模型,以數字「九」的發音為例,相關的 HMM 模型可以圖示如下:

把「九」的發音切分成三個「狀態」(States),分別代表 ㄐ、ㄧ、ㄡ 的發音,每一個狀態可以包含好幾個音框,而每一個音框隸屬於一個狀態的程度,是用一個機率值來表示,稱為「狀態機率」(State Probability)。此外,當一個新的音框進來時,我們可以將此音框留在目前的狀態,也可以將此音框送到下一個狀態,這些行為模式也都是用機率來表示,統稱為「轉移機率」(Transition Probability),其中我們使用「自轉移機率」(Self-transition Probability)來代表新音框留在目前狀態的機率,而用「次轉移機率」(Next-transition Probability)來代表新的音框跳到下一個狀態的機率。
由於每一個音框都會轉成一個語音特徵向量,我們首先使用 VQ 來將這些特徵向量轉成符號(Symbols),換句話說,每一個音框所對應的 VQ 群聚的索引值(Index),即是此音框的符號。若以數學來表示,k = O(i) 即代表 frame i 被分到 cluster k。
定義一些常用的數量:
- frameNum:一段語音所切出的音框個數。
- dim:每一個音框所對應的語音特徵向量的維度(例如基本的 MFCC 有 12 維)。
- stateNum:一個 DHMM 的狀態個數
- symbolNum:符號的個數,也就是 VQ 後的群數
HMM 的參數,就是指「狀態機率」和「轉移機率 Transition Probability」,說明如下:
- 我們通常以矩陣 A 來表示轉移機率,其維度是 stateNum x stateNum,其中 A(i, j) 即是指由狀態 i 跳到狀態 j 的機率值。例如在上圖中,由狀態 1 跳到狀態 2 的機率是 0.3,因此 A(1, 2) = 0.3。一般而言,A(i, j) 滿足下列條件:
- 在進行轉移時,我們只允許搜尋路徑跳到下一個相鄰的狀態,因此 A(i, j) = 0 if j≠i and j≠i+1。
- 對於某一個狀態而言,所有的轉移機率總和為 1,因此 A(i, i) + A(i, i+1) = 1。
- 我們通常以矩陣 B 來表示狀態機率,其維度是 symbolNum x stateNum,B(k,j) 即是指符號 k 隸屬於狀態 j 的機率值。換句話說,B 定義了由「符號」到「狀態」的機率,因此給定第 i 個音框,我們必須先由 O(i) 找出這個音框所對應的符號 k,然後再由 B(k,j) 找出此音框屬於狀態 j 的機率。
假設我們已經知道「九」的 HMM 所包含相關的參數 A 和 B,此時當我們錄音得到一段語音,我們如何算出來此語音隸屬於「九」的機率或程度?如何計算輸入語句和每個模型的相似度?換句話說,我們如何將每個音框分配到各個狀態之中,使得我們能夠得到整段語音最高的機率值?最常用的方法稱為 Viterbi Decoding,這是基於「動態規劃」(Dynamic Programming)的方法,可用數學符號定義如下:
- 目標函數:定義 D(i, j) 是 t(1:i) 和 r(1:j) 之間的最大的機率,t(1:i) 是前 i 個音框的特徵向量所成的矩陣,r(1:j) 則是由前 j 個狀態所形成的 DHMM,對應的最佳路徑是由 (1, 1) 走到 (i, j)。
- 遞迴關係:D(i, j) = B(O(i), j) + max{D(i-1, j)+A(j, j), D(i-1, j-1)+A(j-1, j)}
- 端點條件:D(1, j) = p(1, j) + B(O(1), j), j = 1 ~ stateNum
- 最後答案:D(m, n)

在上述數學式中,我們所用的所有機率都是「對數機率」(Log Probabilities),所以原來必須連乘的數學方程式,都變成了連加,具有下列好處:
- 以加法來取代乘法,降低計算的複雜度。
- 避開了由於連乘所造成的數值誤差。
假設轉移機率 A 和狀態機率 B 已知,那麼經由 Viterbi Decoding,我們可以找到最佳路徑(即是最佳分配方式),使整段路徑的機率值為最大,此機率值及代表輸入語音隸屬於此 DHMM 的機率,若是機率越高,代表此輸入語音越可能是「九」。
有關於 B(O(i),j)的定義,都是「音框 i 隸屬於狀態 j 的機率」,但是在 DHMM 和 CHMM 的算法差異很大,說明如下:
- 在 DHMM,若要計算 B(O(i),j),我們必須先找到音框 i 所對應的符號 O(i),然後在經由查表法查到此符號 O(i) 屬於狀態 j 的機率是 B(O(i), j)。
- 在 CHMM,B(O(i),j) 是由一個連續的機率密度函數所定義。
如何經由大量語料來估測每個 HMM 模型的最佳參數值 A 和 B?
首先,我們必須先定義什麼是「最佳參數」:對某一個特定模型而言,最佳參數值 A 和 B 應能使語料產生最大的對數機率總和。這個定義和最大似然估計(maximum likelihood estimation,縮寫為MLE) 完全相同,也非常合理。
計算最佳參數的方法,稱為 Re-estimation,其原理非常類似 batch k-means (Forgy's method) 的方法,先猜 A 和 B 的值,再反覆進行 Viterbi Decoding,然後再重新估算 A 和 B 的值,如此反覆計算,我們可以證明在疊代過程中,機率總和會一路遞增,直到逼近最佳值。(但是,就如同 k-means Clustering,我們並無法證明所得到的機率值是 Global Maximum,因此在訓練的過程中,可以使用不同的啟始參數,看看是否在反覆疊代後,能夠得到更好的機率總和。)求取參數的方法說明如下:
將所有的訓練語句切出音框,並將每一個音框轉成語音特徵向量,例如 39 維的 MFCC。
對所有語音特徵向量進行向量量化編碼(Vector Quantization, VQ),找出每一個向量所對應的 symbol(此即為對應的中心點或codeword)
先猜一組 A 和 B 的啟始值。如果沒有人工的標示資料,我們可以使用簡單的「均分法」,示意圖如下:

反覆進行下列兩步驟,直到收斂
- Viterbi decoding:在 A 和 B 固定的情況下,利用 Viterbi decoding,找出 n 句「九」的語料所對應的 n 條最佳路徑。
- Re-estimation:利用這 n 條最佳路徑,重新估算 A 和 B。

估算 A 的方法
\( A= \begin{bmatrix} 3/4 & 1/4 & 0 \\ 0 & 4/5 & 1/5 \\ 0 & 0 & 1 \end{bmatrix} \)
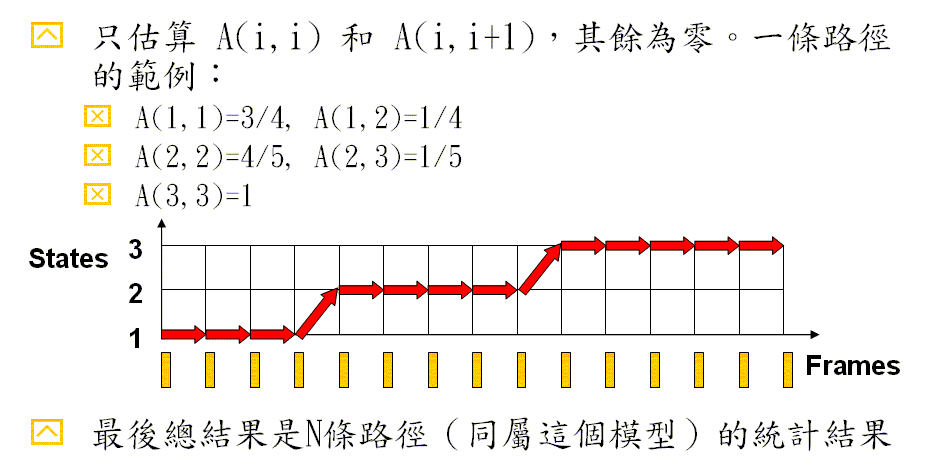
估算 B 的方法:
\( B= \begin{bmatrix} 1/4 & 3/5 & 0 \\ 1/4 & 2/5 & 2/6 \\ 2/4 & 0 & 0 \\ 0 & 0 & 4/6 \end{bmatrix} \)

假設我們的目標函數可以寫成 P(A, B, Path),則上述求參數的方法會讓 P(A, B, Path)逐次遞增,直到收斂,因為:
- 在 A, B 固定時,Viterbi decoding 會找出最佳的路徑,使 P(A, B, Path) 有最大值
- 在路徑(Path)固定時,Re-estimation 會找出最佳的 A, B 值以使 P(A, B, Path)有最大值
沒有留言:
張貼留言