cifar-10 是由 Alex Krizhevsky, Vinod Nair, Geoffery Hinton 收集的一個用於影像辨識資料集,共10類圖片:飛機、汽車、鳥、貓、鹿、狗、青蛙、馬、船、卡車。跟 MNIST 將比, cifar-10 的資料是彩色,雜訊較多,大小不一,角度不同,顏色不同。所以難度比 MNIST 高。
cifar-10 共有 60000 個 32x32 彩色圖像,每一類有 6000 個,共有 50000個訓練圖像及 10000 個測試圖像。
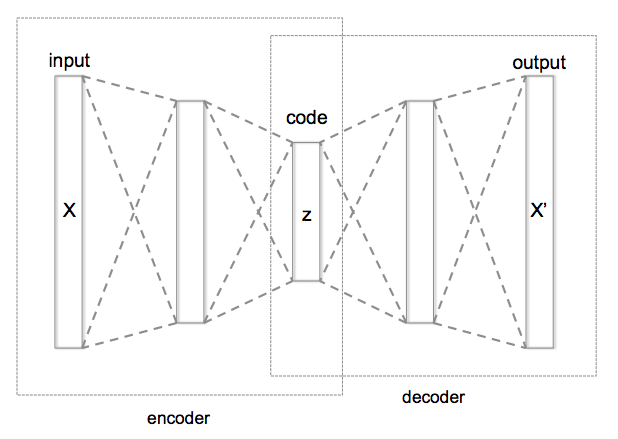
cifar-10 資料集
訓練資料由 images, labels 組成,ylabeltrain 是圖形資料的真實值,每一個數字代表一類圖片
0: airplain, 1: automobile, 2: bird, 3: cat, 4: deer, 5: dog, 6: frog, 7: horse, 8: ship, 9: truck
ximgtrain 的維度如下:有 50000 筆,影像大小為 32x32,第四維因為每一個像素點是 RGB 三原色組成,數值範圍是 0~255,所以是 3
x_img_train.shape: (50000, 32, 32, 3)
import numpy
from keras.datasets import cifar10
import numpy as np
np.random.seed(10)
###########
# 資料準備,載入 cifar10
# 資料會放在 ~/.keras/datasets/cifar-10-batches-py
(x_img_train,y_label_train), (x_img_test, y_label_test)=cifar10.load_data()
# print('train:',len(x_img_train), ', x_img_train.shape:',x_img_train.shape, ', y_label_train:', y_label_train.shape)
# print('test :',len(x_img_test), ', x_img_test.shape:', x_img_test.shape, ', y_label_test:', y_label_test.shape)
## train: 50000 , x_img_train.shape: (50000, 32, 32, 3) , y_label_train: (50000, 1)
## test : 10000 , x_img_test.shape: (10000, 32, 32, 3) , y_label_test: (10000, 1)
# print('x_img_test[0]:', x_img_test[0])
###########
# 查看多筆資料與 label
# 定義 label_dict
label_dict={0:"airplane",1:"automobile",2:"bird",3:"cat",4:"deer",
5:"dog",6:"frog",7:"horse",8:"ship",9:"truck"}
# 產生圖片, label, prediction 的 preview
import matplotlib.pyplot as plt
def plot_images_labels_prediction(images,labels,prediction,idx,filename,num=10):
fig = plt.gcf()
fig.set_size_inches(12, 14)
if num>25: num=25
for i in range(0, num):
ax=plt.subplot(5,5, 1+i)
ax.imshow(images[idx],cmap='binary')
title=str(i)+','+label_dict[labels[i][0]]
if len(prediction)>0:
title+='=>'+label_dict[prediction[i]]
ax.set_title(title,fontsize=10)
ax.set_xticks([]);ax.set_yticks([])
idx+=1
plt.savefig(filename)
# 查看前 10 筆資料
# plot_images_labels_prediction(x_img_train,y_label_train,[],0, 'x_img_train_0_10.png', num=10)
###########
# 對圖片進行預處理
# image normalize
# 查看圖片的第一個點
# print('x_img_train[0][0][0]=', x_img_train[0][0][0])
## x_img_train[0][0][0]= [59 62 63]
# normalize 標準化,可提升模型的準確度
x_img_train_normalize = x_img_train.astype('float32') / 255.0
x_img_test_normalize = x_img_test.astype('float32') / 255.0
# print('x_img_train_normalize[0][0][0]=', x_img_train_normalize[0][0][0])
## x_img_train_normalize[0][0][0]= [0.23137255 0.24313726 0.24705882]
## 將 label 轉為 one hot encoding
from keras.utils import np_utils
y_label_train_OneHot = np_utils.to_categorical(y_label_train)
y_label_test_OneHot = np_utils.to_categorical(y_label_test)
# print('y_label_train[:5]=', y_label_train[:5])
# print('y_label_train_OneHot.shape=', y_label_train_OneHot.shape)
# print('y_label_train_OneHot[:5]', y_label_train_OneHot[:5])
####
# y_label_train[:5]= [[6]
# [9]
# [9]
# [4]
# [1]]
# y_label_train_OneHot.shape= (50000, 10)
# y_label_train_OneHot[:5] [[0. 0. 0. 0. 0. 0. 1. 0. 0. 0.]
# [0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
# [0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
# [0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
# [0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]]
cifar-10 CNN
模型對應的程式
列印 model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 32, 32, 32) 896
_________________________________________________________________
dropout_1 (Dropout) (None, 32, 32, 32) 0
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 16, 16, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 16, 16, 64) 18496
_________________________________________________________________
dropout_2 (Dropout) (None, 16, 16, 64) 0
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 8, 8, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 4096) 0
_________________________________________________________________
dropout_3 (Dropout) (None, 4096) 0
_________________________________________________________________
dense_1 (Dense) (None, 1024) 4195328
_________________________________________________________________
dropout_4 (Dropout) (None, 1024) 0
_________________________________________________________________
dense_2 (Dense) (None, 10) 10250
=================================================================
Total params: 4,224,970
Trainable params: 4,224,970
Non-trainable params: 0
import numpy
from keras.datasets import cifar10
import numpy as np
np.random.seed(10)
###########
# 資料準備,載入 cifar10
# 資料會放在 ~/.keras/datasets/cifar-10-batches-py
(x_img_train,y_label_train), (x_img_test, y_label_test)=cifar10.load_data()
###########
# 對圖片進行預處理
# normalize 標準化,可提升模型的準確度
x_img_train_normalize = x_img_train.astype('float32') / 255.0
x_img_test_normalize = x_img_test.astype('float32') / 255.0
## 將 label 轉為 one hot encoding
from keras.utils import np_utils
y_label_train_OneHot = np_utils.to_categorical(y_label_train)
y_label_test_OneHot = np_utils.to_categorical(y_label_test)
#########
# 建立模型
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D, ZeroPadding2D
model = Sequential()
#卷積層 1與池化層1
## 輸入影像為 32x32,會產生 32 個影像,結果仍是 32x32
## filters=32 是隨機產生 32 個濾鏡 filter weight
## kernel_size=(3,3) 濾鏡大小為 3x3
## padding='same' 讓卷積運算的結果產生的影像大小不變
## activation='relu' 設定 ReLU activation function
model.add(Conv2D(filters=32,kernel_size=(3,3),
input_shape=(32, 32,3),
activation='relu',
padding='same'))
## 加入 Dropout 避免 overfitting
## 0.25 是每一次訓練迭代時,會隨機丟棄 25% 神經元
model.add(Dropout(rate=0.25))
## 池化層1
## pool_size 是縮減取樣,會縮小為 16x16,仍為 32 個
model.add(MaxPooling2D(pool_size=(2, 2)))
#卷積層2與池化層2
## 將 32 個影像,轉換為 64 個
model.add(Conv2D(filters=64, kernel_size=(3, 3),
activation='relu', padding='same'))
model.add(Dropout(0.25))
## 縮小影像,結果為 8x8 共 64 個影像
model.add(MaxPooling2D(pool_size=(2, 2)))
#Step3 建立神經網路(平坦層、隱藏層、輸出層)
## 將 64 個 8x8 影像轉換為 1 維,64*8*8=4096 個 float
model.add(Flatten())
## 加入 Dropout,隨機丟棄 25%
model.add(Dropout(rate=0.25))
## 建立隱藏層,共 1024 個神經元
model.add(Dense(1024, activation='relu'))
model.add(Dropout(rate=0.25))
## 輸出層
model.add(Dense(10, activation='softmax'))
# print(model.summary())
####################
import matplotlib.pyplot as plt
def show_train_history(train_acc,test_acc, filename):
plt.gcf()
plt.plot(train_history.history[train_acc])
plt.plot(train_history.history[test_acc])
plt.title('Train History')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.savefig(filename)
#### 判斷是否可載入已經訓練好的模型
try:
model.load_weights("SaveModel/cifarCnnModelnew.h5")
print("載入模型成功!繼續訓練模型")
except :
print("載入模型失敗!開始訓練一個新模型")
#### 進行訓練
model.compile(loss='categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])
train_history=model.fit(x_img_train_normalize, y_label_train_OneHot,
validation_split=0.2,
epochs=10, batch_size=128, verbose=1)
show_train_history('accuracy','val_accuracy', 'accuracy.png')
show_train_history('loss','val_loss', 'loss.png')
#######
# 評估模型準確率
scores = model.evaluate(x_img_test_normalize,
y_label_test_OneHot, verbose=0)
print("scores[1]=", scores[1])
## 進行預測
prediction=model.predict_classes(x_img_test_normalize)
###########
# 查看多筆資料與 label
# 定義 label_dict
label_dict={0:"airplane",1:"automobile",2:"bird",3:"cat",4:"deer",
5:"dog",6:"frog",7:"horse",8:"ship",9:"truck"}
# 產生圖片, label, prediction 的 preview
import matplotlib.pyplot as plt
def plot_images_labels_prediction(images,labels,prediction,idx,filename,num=10):
fig = plt.gcf()
fig.set_size_inches(12, 14)
if num>25: num=25
for i in range(0, num):
ax=plt.subplot(5,5, 1+i)
ax.imshow(images[idx],cmap='binary')
title=str(i)+','+label_dict[labels[i][0]]
if len(prediction)>0:
title+='=>'+label_dict[prediction[i]]
ax.set_title(title,fontsize=10)
ax.set_xticks([]);ax.set_yticks([])
idx+=1
plt.savefig(filename)
## 列印前 10 筆預測結果
plot_images_labels_prediction(x_img_test,y_label_test,prediction,0,'prediction.png', num=10)
# 查看預測機率
Predicted_Probability=model.predict(x_img_test_normalize)
# y: 真實值
# prediciton: 預測結果
# x_img: 預測的影像
# Predicted_Probability: 預測機率
# i: 資料 index
def show_Predicted_Probability(y,prediction,
x_img,Predicted_Probability,i):
print('-------------------')
print('label:',label_dict[y[i][0]],
'predict:',label_dict[prediction[i]])
fig = plt.gcf()
plt.figure(figsize=(2,2))
plt.imshow(np.reshape(x_img_test[i],(32, 32,3)))
plt.savefig(""+str(i)+".png")
for j in range(10):
print(label_dict[j]+
' Probability:%1.9f'%(Predicted_Probability[i][j]))
show_Predicted_Probability(y_label_test,prediction,
x_img_test,Predicted_Probability,0)
# label: cat predict: cat
# airplane Probability:0.000472784
# automobile Probability:0.001096419
# bird Probability:0.008890972
# cat Probability:0.852500975
# deer Probability:0.010386771
# dog Probability:0.074663654
# frog Probability:0.035179924
# horse Probability:0.002779935
# ship Probability:0.010328157
# truck Probability:0.003700291
show_Predicted_Probability(y_label_test,prediction,
x_img_test,Predicted_Probability,3)
# label: airplane predict: airplane
# airplane Probability:0.616022110
# automobile Probability:0.032570492
# bird Probability:0.073217131
# cat Probability:0.006363209
# deer Probability:0.030436775
# dog Probability:0.001208493
# frog Probability:0.001075586
# horse Probability:0.001057812
# ship Probability:0.235320851
# truck Probability:0.002727570
#####
# confusion matrix
print("prediction.shape=", str(prediction.shape), ", y_label_test.shape=",str(y_label_test.shape))
## prediction.shape= (10000,) , y_label_test.shape= (10000, 1)
# 將y_label_test 轉為 一行, 多個 columns
y_label_test.reshape(-1)
import pandas as pd
print(label_dict)
crosstab1 = pd.crosstab(y_label_test.reshape(-1),prediction,
rownames=['label'],colnames=['predict'])
print()
print("-----crosstab1------")
print(crosstab1)
# -----crosstab1------
# predict 0 1 2 3 4 5 6 7 8 9
# label
# 0 742 13 45 22 29 7 28 9 53 52
# 1 10 814 8 12 7 13 24 3 13 96
# 2 56 3 541 62 121 71 114 23 3 6
# 3 13 7 38 505 82 179 141 16 6 13
# 4 7 2 33 51 736 35 102 26 7 1
# 5 6 1 30 160 63 656 62 15 1 6
# 6 0 2 13 27 13 18 923 1 1 2
# 7 8 0 27 42 93 86 29 709 0 6
# 8 45 40 22 29 16 10 23 2 778 35
# 9 22 62 4 27 6 19 22 8 15 815
# 將模型儲存為 JSON
import os
if not os.path.exists('SaveModel'):
os.makedirs('SaveModel')
model_json = model.to_json()
with open("SaveModel/cifarCnnModelnew.json", "w") as json_file:
json_file.write(model_json)
# 將模型儲存為 YAML
model_yaml = model.to_yaml()
with open("SaveModel/cifarCnnModelnew.yaml", "w") as yaml_file:
yaml_file.write(model_yaml)
# 將模型儲存為 h5
model.save_weights("SaveModel/cifarCnnModelnew.h5")
print("Saved model to disk")
Train on 40000 samples, validate on 10000 samples
Epoch 1/10
40000/40000 [==============================] - 162s 4ms/step - loss: 1.0503 - accuracy: 0.6292 - val_loss: 1.1154 - val_accuracy: 0.6282
Epoch 2/10
40000/40000 [==============================] - 167s 4ms/step - loss: 1.0259 - accuracy: 0.6337 - val_loss: 1.0459 - val_accuracy: 0.6620
Epoch 3/10
40000/40000 [==============================] - 177s 4ms/step - loss: 0.9121 - accuracy: 0.6802 - val_loss: 0.9687 - val_accuracy: 0.6851
Epoch 4/10
40000/40000 [==============================] - 159s 4ms/step - loss: 0.8165 - accuracy: 0.7133 - val_loss: 0.9097 - val_accuracy: 0.7079
Epoch 5/10
40000/40000 [==============================] - 158s 4ms/step - loss: 0.7338 - accuracy: 0.7423 - val_loss: 0.8498 - val_accuracy: 0.7269
Epoch 6/10
40000/40000 [==============================] - 159s 4ms/step - loss: 0.6554 - accuracy: 0.7695 - val_loss: 0.8093 - val_accuracy: 0.7297
Epoch 7/10
40000/40000 [==============================] - 149s 4ms/step - loss: 0.5759 - accuracy: 0.7978 - val_loss: 0.8047 - val_accuracy: 0.7312
Epoch 8/10
40000/40000 [==============================] - 152s 4ms/step - loss: 0.5092 - accuracy: 0.8216 - val_loss: 0.7822 - val_accuracy: 0.7367
Epoch 9/10
40000/40000 [==============================] - 146s 4ms/step - loss: 0.4505 - accuracy: 0.8414 - val_loss: 0.7737 - val_accuracy: 0.7375
Epoch 10/10
40000/40000 [==============================] - 160s 4ms/step - loss: 0.3891 - accuracy: 0.8638 - val_loss: 0.7935 - val_accuracy: 0.7317
scores[1]= 0.7218999862670898
cifar-10 CNN 三次卷積
為增加正確率,修改為三次卷積
epochs 改為 50 次,但這樣會讓程式要跑很久,可先用 1 測試
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 32, 32, 32) 896
_________________________________________________________________
dropout_1 (Dropout) (None, 32, 32, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 32, 32, 32) 9248
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 16, 16, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 16, 16, 64) 18496
_________________________________________________________________
dropout_2 (Dropout) (None, 16, 16, 64) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 16, 16, 64) 36928
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 8, 8, 64) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 8, 8, 128) 73856
_________________________________________________________________
dropout_3 (Dropout) (None, 8, 8, 128) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 8, 8, 128) 147584
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 4, 4, 128) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 2048) 0
_________________________________________________________________
dropout_4 (Dropout) (None, 2048) 0
_________________________________________________________________
dense_1 (Dense) (None, 2500) 5122500
_________________________________________________________________
dropout_5 (Dropout) (None, 2500) 0
_________________________________________________________________
dense_2 (Dense) (None, 1500) 3751500
_________________________________________________________________
dropout_6 (Dropout) (None, 1500) 0
_________________________________________________________________
dense_3 (Dense) (None, 10) 15010
=================================================================
Total params: 9,176,018
Trainable params: 9,176,018
Non-trainable params: 0
import numpy
from keras.datasets import cifar10
import numpy as np
np.random.seed(10)
###########
# 資料準備,載入 cifar10
# 資料會放在 ~/.keras/datasets/cifar-10-batches-py
(x_img_train,y_label_train), (x_img_test, y_label_test)=cifar10.load_data()
###########
# 對圖片進行預處理
# normalize 標準化,可提升模型的準確度
x_img_train_normalize = x_img_train.astype('float32') / 255.0
x_img_test_normalize = x_img_test.astype('float32') / 255.0
## 將 label 轉為 one hot encoding
from keras.utils import np_utils
y_label_train_OneHot = np_utils.to_categorical(y_label_train)
y_label_test_OneHot = np_utils.to_categorical(y_label_test)
#########
# 建立模型
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D, ZeroPadding2D
model = Sequential()
#卷積層 1與池化層1
model.add(Conv2D(filters=32,kernel_size=(3, 3),input_shape=(32, 32,3),
activation='relu', padding='same'))
model.add(Dropout(0.3))
model.add(Conv2D(filters=32, kernel_size=(3, 3),
activation='relu', padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2)))
#卷積層2與池化層2
model.add(Conv2D(filters=64, kernel_size=(3, 3),
activation='relu', padding='same'))
model.add(Dropout(0.3))
model.add(Conv2D(filters=64, kernel_size=(3, 3),
activation='relu', padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2)))
#卷積層3與池化層3
model.add(Conv2D(filters=128, kernel_size=(3, 3),
activation='relu', padding='same'))
model.add(Dropout(0.3))
model.add(Conv2D(filters=128, kernel_size=(3, 3),
activation='relu', padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2)))
#Step3 建立神經網路(平坦層、隱藏層、輸出層)
model.add(Flatten())
model.add(Dropout(0.3))
model.add(Dense(2500, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(1500, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(10, activation='softmax'))
print(model.summary())
####################
import matplotlib.pyplot as plt
def show_train_history(train_acc,test_acc, filename):
plt.clf()
plt.gcf()
plt.plot(train_history.history[train_acc])
plt.plot(train_history.history[test_acc])
plt.title('Train History')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.savefig(filename)
#### 判斷是否可載入已經訓練好的模型
try:
model.load_weights("SaveModel/cifarCnnModelnew.h5")
print("載入模型成功!繼續訓練模型")
except :
print("載入模型失敗!開始訓練一個新模型")
#### 進行訓練
model.compile(loss='categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])
train_history=model.fit(x_img_train_normalize, y_label_train_OneHot,
validation_split=0.2,
epochs=1, batch_size=300, verbose=1)
show_train_history('accuracy','val_accuracy', 'accuracy.png')
show_train_history('loss','val_loss', 'loss.png')
#######
# 評估模型準確率
scores = model.evaluate(x_img_test_normalize,
y_label_test_OneHot, verbose=0)
print("scores[1]=", scores[1])
## 進行預測
prediction=model.predict_classes(x_img_test_normalize)
###########
# 查看多筆資料與 label
# 定義 label_dict
label_dict={0:"airplane",1:"automobile",2:"bird",3:"cat",4:"deer",
5:"dog",6:"frog",7:"horse",8:"ship",9:"truck"}
# 產生圖片, label, prediction 的 preview
import matplotlib.pyplot as plt
def plot_images_labels_prediction(images,labels,prediction,idx,filename,num=10):
plt.clf()
fig = plt.gcf()
fig.set_size_inches(12, 14)
if num>25: num=25
for i in range(0, num):
ax=plt.subplot(5,5, 1+i)
ax.imshow(images[idx],cmap='binary')
title=str(i)+','+label_dict[labels[i][0]]
if len(prediction)>0:
title+='=>'+label_dict[prediction[i]]
ax.set_title(title,fontsize=10)
ax.set_xticks([]);ax.set_yticks([])
idx+=1
plt.savefig(filename)
## 列印前 10 筆預測結果
plot_images_labels_prediction(x_img_test,y_label_test,prediction,0,'prediction.png', num=10)
# 查看預測機率
Predicted_Probability=model.predict(x_img_test_normalize)
# y: 真實值
# prediciton: 預測結果
# x_img: 預測的影像
# Predicted_Probability: 預測機率
# i: 資料 index
def show_Predicted_Probability(y,prediction,
x_img,Predicted_Probability,i):
print('-------------------')
print('label:',label_dict[y[i][0]],
'predict:',label_dict[prediction[i]])
plt.clf()
fig = plt.gcf()
plt.figure(figsize=(2,2))
plt.imshow(np.reshape(x_img_test[i],(32, 32,3)))
plt.savefig(""+str(i)+".png")
for j in range(10):
print(label_dict[j]+
' Probability:%1.9f'%(Predicted_Probability[i][j]))
show_Predicted_Probability(y_label_test,prediction,
x_img_test,Predicted_Probability,0)
show_Predicted_Probability(y_label_test,prediction,
x_img_test,Predicted_Probability,3)
#####
# confusion matrix
print("prediction.shape=", str(prediction.shape), ", y_label_test.shape=",str(y_label_test.shape))
# 將y_label_test 轉為 一行, 多個 columns
y_label_test.reshape(-1)
import pandas as pd
print(label_dict)
crosstab1 = pd.crosstab(y_label_test.reshape(-1),prediction,
rownames=['label'],colnames=['predict'])
print()
print("-----crosstab1------")
print(crosstab1)
# 將模型儲存為 JSON
import os
if not os.path.exists('SaveModel'):
os.makedirs('SaveModel')
model_json = model.to_json()
with open("SaveModel/cifarCnnModelnew.json", "w") as json_file:
json_file.write(model_json)
# 將模型儲存為 YAML
model_yaml = model.to_yaml()
with open("SaveModel/cifarCnnModelnew.yaml", "w") as yaml_file:
yaml_file.write(model_yaml)
# 將模型儲存為 h5
model.save_weights("SaveModel/cifarCnnModelnew.h5")
print("Saved model to disk")
Note
程式放到 CUDA 機器上,安裝 tensorflow-gpu 出現 error 的解決方式
在 tensorflow-gpu 出現 error
Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
ref: https://davistseng.blogspot.com/2019/11/tensorflow-2.html
import tensorflow as tf
def solve_cudnn_error():
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
try:
# Currently, memory growth needs to be the same across GPUs
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
logical_gpus = tf.config.experimental.list_logical_devices('GPU')
print(len(gpus), "Physical GPUs,", len(logical_gpus), "Logical GPUs")
except RuntimeError as e:
# Memory growth must be set before GPUs have been initialized
print(e)
solve_cudnn_error()
pandas error: No module named '_bz2'
ref: https://stackoverflow.com/questions/12806122/missing-python-bz2-module
cp /usr/lib64/python3.6/lib-dynload/_bz2.cpython-36m-x86_64-linux-gnu.so /usr/local/lib/python3.6/lib-dynload/
references
TensorFlow+Keras深度學習人工智慧實務應用